Experiments in the paper
1 Single-reference
1.1 Style transfer
Compare the performance of non-parallel (text contents of source and target are irrelevant) style transfer between the original model and ours (intercross).
Reference audios are randomly chosen from a same speaker.
These demos are corresponding to Figure 5 in our paper.
| Reference audios | ||||
|---|---|---|---|---|
| Original | ||||
| Intercross |
Synthesized text: 正提高自己的能力,为了更好的为你解决难题。
More non-parallel style transfer cases over different speakers and different text contents.
| speaker1 | speaker2 | speaker3 | speaker4 | |
|---|---|---|---|---|
| Reference audios | ||||
| Text1 | ||||
| Text2 | ||||
| Text3 |
Text1: 我可不会。
Text2: 南开永远年轻,她的学生也都充满活力。
Text3: “你知道,我是用稻草填塞的,所以我没有脑子。”他悲伤的回答。
1.2 Style control
Visualization of gradual changes in mel-spectrogram. We present GIFs of text1, text2 and text3
from left to right for intuitive view.
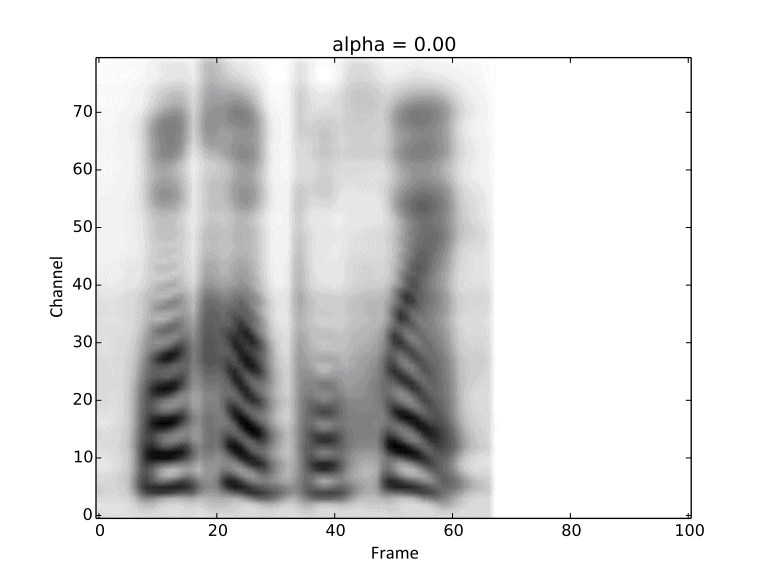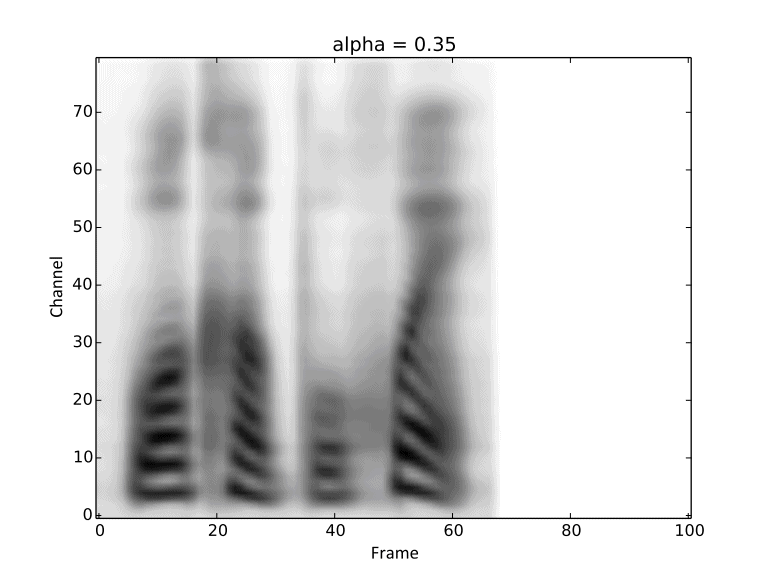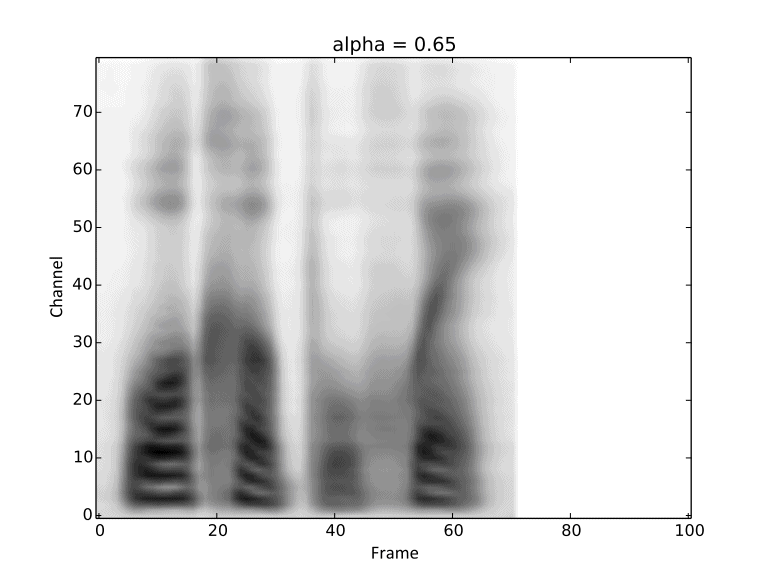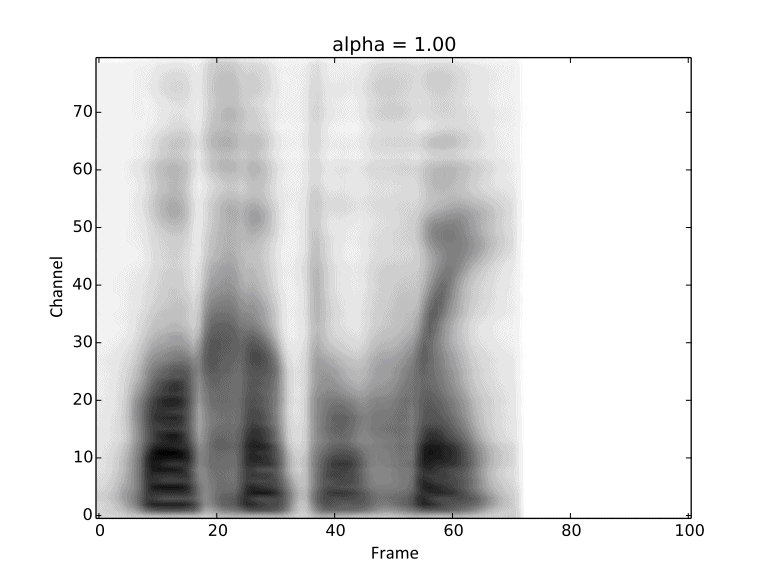
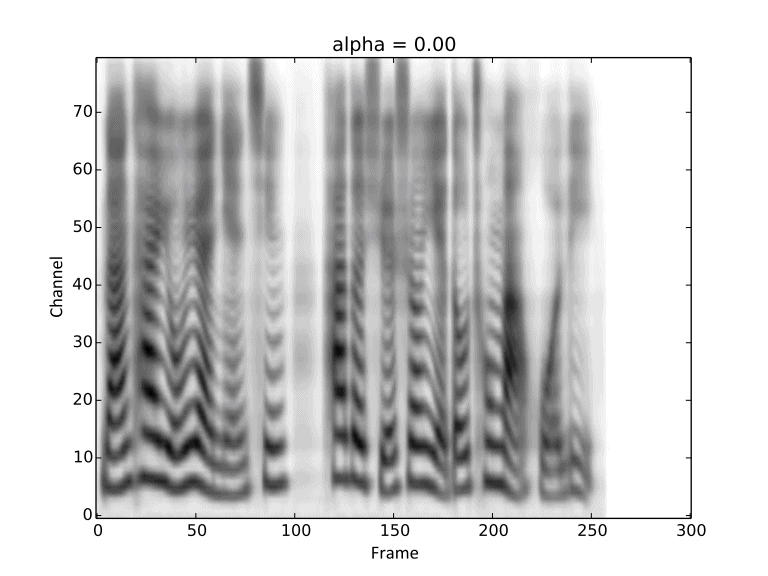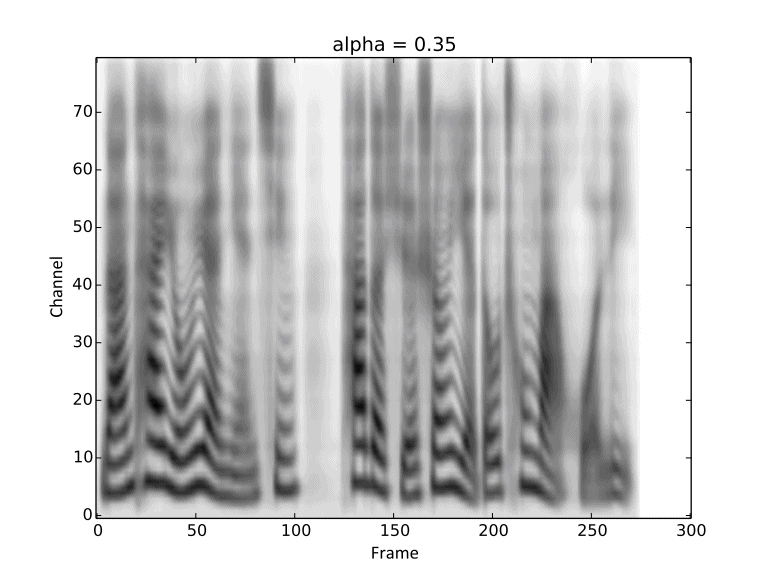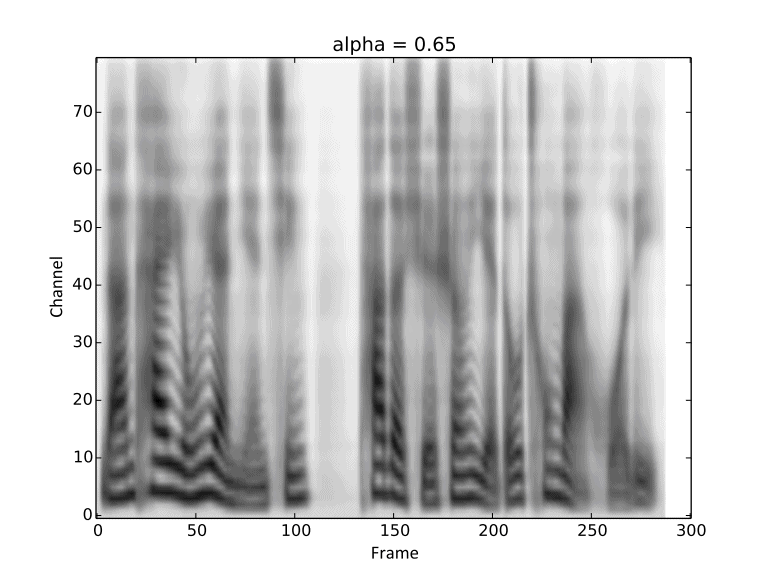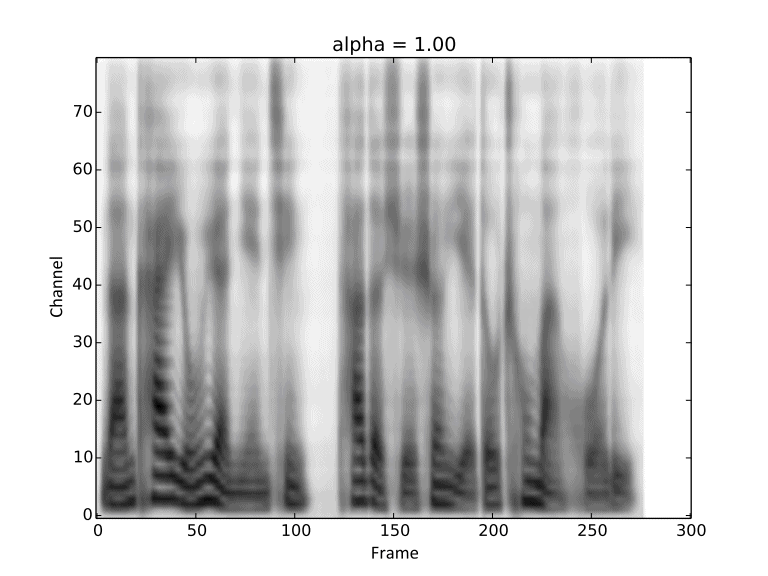
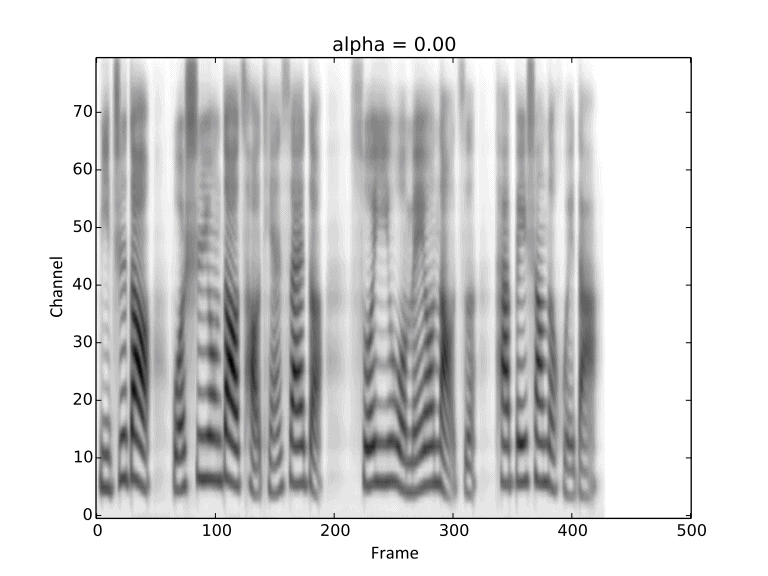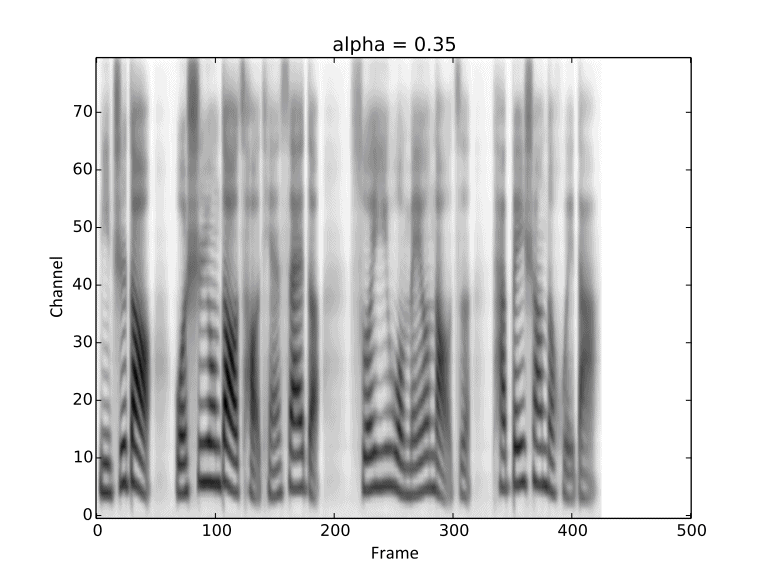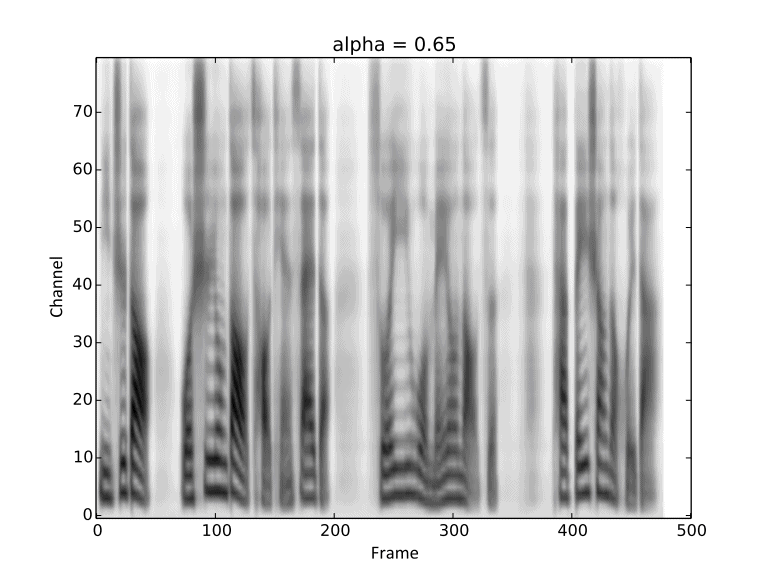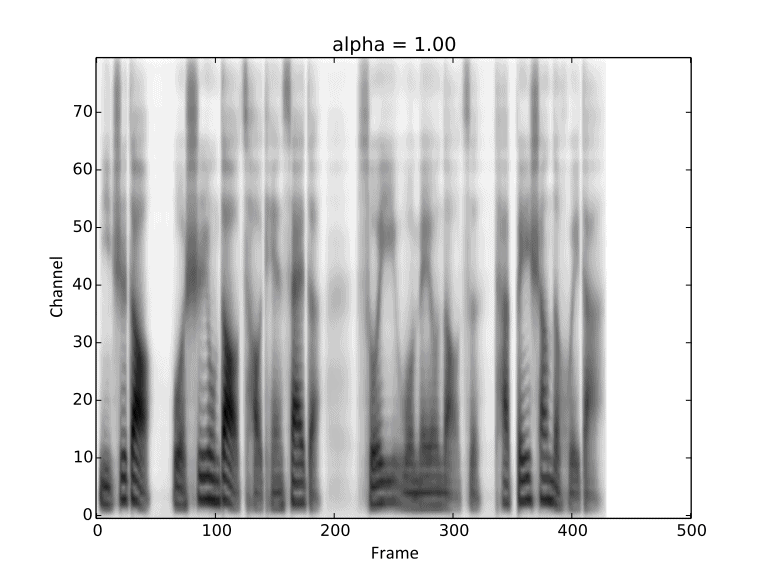
We reuse the reference audios of speaker1 and speaker4 in above experiments.
Then we conduct linear interpolation between them, introduced in Section 2.5 in our paper.
These demos are corresponding to Figure 6 in the paper.
| speaker1, α = 0.0 | α = 0.25 | α = 0.5 | α = 0.75 | speaker4, α = 1.0 | |
|---|---|---|---|---|---|
| Text1 | |||||
| Text2 | |||||
| Text3 |
Text1: 我可不会。
Text2: 南开永远年轻,她的学生也都充满活力。
Text3: “你知道,我是用稻草填塞的,所以我没有脑子。”他悲伤的回答。
1.3 Random sampling
These demos are generated by random sampling introduced in Section 2.5 in our paper.
Synthesized text: 我是发音人随机采样的测试文本。
1.4 One-shot & few-shot
We use audios from extra 20 speakers to conduct one-shot speaker conversion introduced in section 3.1.4. We see
not all of them can be converted success. We present two success cases and two failed cases here.
| Reference audios | Text1 | Text2 | Text3 | |
|---|---|---|---|---|
| Case1 (success) | ||||
| Case2 (success) | ||||
| Case3 (failed) | ||||
| Case4 (failed) |
Text1: 我赢了所有人,但却输掉了你。
Text2: 我心里就甜滋滋的,像吃了蜜一样。
Text3: 他眼里迸射出仇恨的火花。
We conduct few-shot speaker conversion over the speaker of failed cases in one-shot speaker conversion.
We using different number of utterances to fine-tune the models and evaluate their performance.
| Utterance number | Text1 | Text2 | Text3 | |
|---|---|---|---|---|
| Case3 | 10 | |||
| 20 | ||||
| Case4 | 10 | |||
| 20 |
Text1: 我赢了所有人,但却输掉了你。
Text2: 我心里就甜滋滋的,像吃了蜜一样。
Text3: 他眼里迸射出仇恨的火花。
2 Multi-reference
2.1 Style Control
In the experiments, we control two styles: speaker and prosody.
We define 5 prosodies by different speaking scenes: news, story, radio, poetry, call-center.
We briefly conclude their features as follows.
news: relative fast; formal.
story: many transitions and breaks.
radio: relative slow; deep and attractive voice.
poetry: slow; obeys rules of rhyming.
call-center: relative fast; sweet;
We conduct parallel multi-styles control. As table 1 in our paper shows, speaker F17 and speaker M5 both have styles
news and radio.
Formally, we generates audios according to following equations.
speaker = F17 + α 1 * (M5 - F17)
prosody = Radio + α 2 * (News - Radio)
These demos are corresponding to Figure 8(a) in the paper.
| α 1 = 0.0 | α 1 = 0.25 | α 1 = 0.5 | α 1 = 0.75 | α 1 = 1.0 | |
|---|---|---|---|---|---|
| α 2 = 0.0 | |||||
| α 2 = 0.25 | |||||
| α 2 = 0.5 | |||||
| α 2 = 0.75 | |||||
| α 2 = 1.0 |
Synthesized text: 2018已经成为大家共同的回忆,2019年的“冰与火之歌”正在唱响。
We conduct non-parallel multi-styles control. As table 1 in our paper shows, speaker F4 only has style call-center and speaker
M2 only has style poetry. And we are going to generate non-existent styles for the speakers.
Formally, we generates audios according to following equations.
speaker = M2 + α 1 * (F4 – M2)
prosody = poetry + α 2 * (callcenter - poetry)
These demos are corresponding to Figure 8(b) in the paper.
| α 1 = 0.0 | α 1 = 0.25 | α 1 = 0.5 | α 1 = 0.75 | α 1 = 1.0 | |
|---|---|---|---|---|---|
| α 2 = 0.0 | |||||
| α 2 = 0.25 | |||||
| α 2 = 0.5 | |||||
| α 2 = 0.75 | |||||
| α 2 = 1.0 |
Synthesized text: 2018已经成为大家共同的回忆,2019年的“冰与火之歌”正在唱响。